

前言
本篇的内容接上一篇 基础② ,主要讲的是爬虫登录,cookie持续登录。
我这里不重复注意事项,如果你有不明确的请去看一下上一篇爬虫基础。
在上网过程中,比如遇到了需要登录才能获取到的信息,就比如学校抢课网站,淘宝网,某些小网站都倾向于把数据都弄成登录才能访问,服务器就可以不用买太好的。
那么遇到这些问题,我们也只能让我们的爬虫程序也学会登录了。
登录有几种基本方式:
就是你通过POST请求把你的登录凭证交给服务器,服务器返还给你一个临时token,你每次请求数据带上这个临时token就行。
就是cookie登录
我们都知道,cookies是指是浏览网站时由网络服务器创建并由网页浏览器存放在用户计算机或其他设备的小文本文件。
Cookie使Web服务器能在用户的设备存储状态信息(如添加到在线商店购物车中的商品)或跟踪用户的浏览活动(如点击特定按钮、登录或记录历史)。
单次登录
我这里拿某个小网站举例子,因为大部分网站都有验证码,验证码的问题未来会说怎么解决。
示例网站:练习
注册好后直接来到登录网址
进入网站首先打开控制台窗口,定位到网络选项监听。
然后输入你刚刚注册的用户名和密码登录,这个时候应该可以在旁边监听窗口看到你的登录数据包:
可以看到这种处于上面,在你点击登录按钮瞬间触发的数据包多半就是你需要的。请求方法也是POST
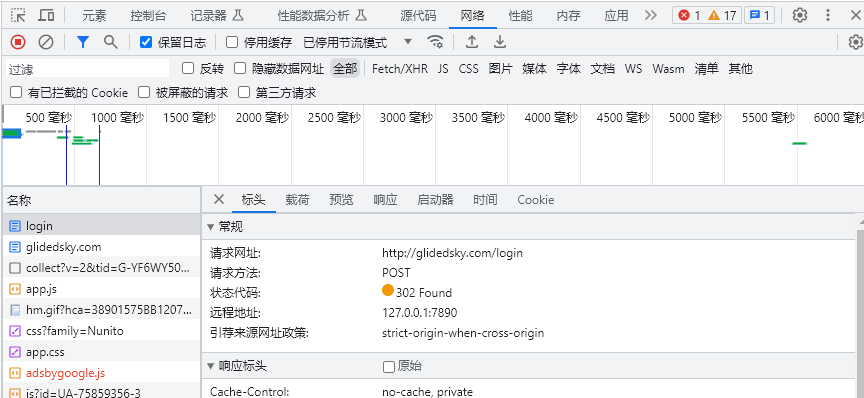
我们点击请求网址上面的载荷选项,就可以看到我们向服务器提交的信息了。
一般情况下,我们向服务器只会提交用户名,密码,验证码之类的信息,有时候会提交我们的token,加密数据等等之类的信息。
这次我们向这个网站提交的是token,用户名,密码。如下:
最后一个remember是你勾选了记住密码才会有的。
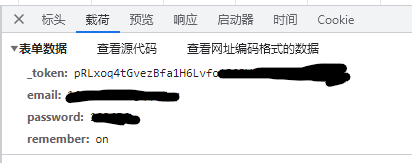
首先我们得先知道这里提交的所有资料代表什么,可不可以随机生成,这样子方便我们程序操作。
比如这里的token在登录页面元素的head标签里面找到。
<header>
<meta name="csrf-token" content="VyP11asd089lvL1NlI7kldPh8UMtJJb9LUQffjWd">
</header>
知道了提交的东西,我们来梳理一下登录流程:
- 向网站请求一个登录网页,提取token
- 将token放进POST请求提交的数据里面提交给服务器
- 访问我们想要的资源
登录操作
根据上面的流程,我们首先获取token:
import requests
from lxml import etree
cs = requests.Session() #创建一个客户端会话,相当于持久化版本的requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
token = cs.get(url='http://glidedsky.com/login',header=headers).text
token = etree.HTML(token)
token = token.xpath('/html/head/meta[3]/@content')[0] #这里的'/@content'是指把标签中对应名字的属性内容提取出来。
```会话的使用方法和requests模块一样.
唯一区别是你登录一次后他会记录从服务器发送过来的信息并存储起来,
在程序运行期间再次用同一个会话发起请求时会自动把这些信息发送过去,
也就是自动实现登录保持功能。```
刚刚我们已经拿到了token,存储到了token变量中,接下来我们的程序需要进行POST把获取到的数据发送到服务器进行登录,下面的程序接着上面的就可以正常运行。
data = {
'_token' : token,
'email' : 'xxxxx@xxxxx',
'password' : 'xxxxx'
}
cs.post(url = 'http://glidedsky.com/login' , headers=headers , data=data)
进行了上面的登录程序后,下面根据我们的爬虫需要进行相关爬取即可。
要注意的是不可以用requests请求了,不然上面登录等于白费,得用cs代替requests模块即可。
cookie持续登录
这里得看你是怎样对待cookie了。
如果直接写死在程序里面,更新不方便,每次cookie失效又得重新写个cookie进去,非常不方便,还不如上面的单次登录。
如果你是放在网上,可以远程获取这个cookie,也可以在线更新,而程序只要按照一个固定的URL请求就可以得到cookie,方便是方便,但总所周知,网上等于透明,你放上去就是把你的号放上去,十分不推荐。
推荐 如果你的账号不那么重要,只是做个信息查询工具的话不需要那么高安全性的话,可以尝试将cookie加密之后再存放在网上,这里推荐除了完全对称加密,其他主流加密方法都可以一试,不过你要真的不怂,完全对称加密也行。
上面工作弄完后,接下来就简单了,假设你要访问某个网站,你只需要在浏览器上面登录,然后打开控制台,定位到网络选项卡监听,在你刷新一次,这样子你就可以在请求标头里面找到cookie。
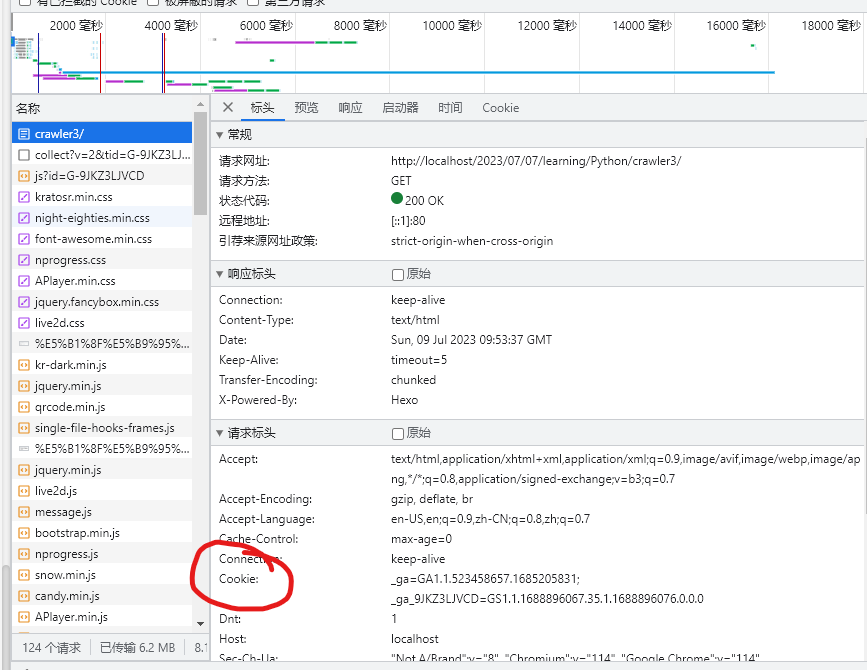
我们只需要在程序标头里面加上cookie即可,示例如下:
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'cookie': cookie
}
requests.get(url='url' , headers=headers)
是不是很方便?不过前面获取cookie的过程被省略了,发挥自己实力的时候到了
alertbox success “好的这就是爬虫登录的所有内容了,感谢你的观看
如果有建议或者错误请指出帮助我们改正,感谢。